I’ve found that if I’m using scala.concurrent.Future in my code, I can get some really easy performance gains by just switching to scalaz.concurrent.Task instead, particularly if I’m chaining them with map or flatMap calls, or with for comprehensions.
Jumping into thread pools
Every Future is basically some work that needs to be submitted to a thread pool. When you call futureA.flatMap(a => futureB), both Future[A] and Future[B] need to be submitted to the thread pool, even though they are not running concurrently and could theoretically run on the same thread. This context switching takes a bit of time.
Jumping on trampolines
With scalaz.concurrent.Task you have a bit more control over when you submit work to a thread pool and when you actually want to continue on the thread that is already executing a Task. When you say taskA.flatMap(a => taskB), the taskB will by default just continue running on the same thread that was already executing taskA. If you explicitly want to dip into the thread pool, you have to say so with Task.fork.
This works since a Task is not a concurrently running computation. It’s a description of a computation—a sequential list of instructions that may include instructions to submit some of the work to thread pools. The work is actually executed by a tight loop in Task’s run method. This loop is called a trampoline since every step in the Task (that is, every subtask) returns control to this loop.
Jumping on a trampoline is a lot faster than jumping into a thread pool, so whenever we’re composing Futures with map and flatMap, we can just switch to Task and make our code faster.
Making fewer jumps
But sometimes we know that we want to continue on the same thread and we don’t want to spend the time jumping on a trampoline at every step. To demonstrate this, I’ll use the Ackermann function. This is not necessarily a good use case for Future but it shows the difference well.
1 2 3 4 5 6 | |
This function is supposed to terminate for all positive m and n, but if they are modestly large, this recursive definition overflows the stack. We could use futures to alleviate this, jumping into a thread pool instead of making a stack frame at each step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Since there’s no actual concurrency going on here, we can make this instantly faster by switching to Task instead, using a trampoline instead of a thread pool:
1 2 3 4 5 6 7 8 9 10 11 | |
But even here, we’re making too many jumps back to the trampoline with suspend. We don’t actually need to suspend and return control to the trampoline at each step. We only need to do it enough times to avoid overflowing the stack. Let’s say we know how large our stack can grow:
1
| |
We can then keep track of how many recursive calls we’ve made, and jump on the trampoline only when we need to:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
How fast is it?
I did some comparisons using Caliper and made this pretty graph for you:
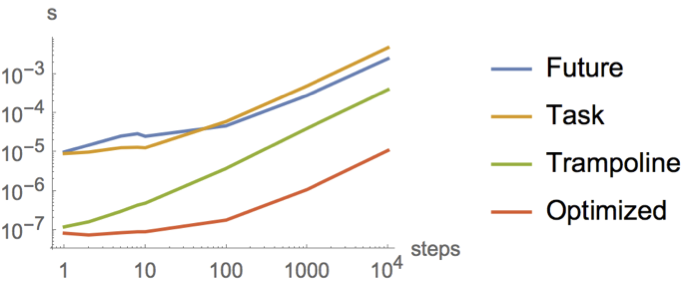
The horizontal axis is the number of steps, and the vertical axis is the mean time that number of steps took over a few thousand runs.
This graph shows that Task is slightly faster than Future for submitting to thread pools (blue and yellow lines marked Future and Task respectively) only for very small tasks; up to about when you get to 50 steps, when (on my Macbook) both futures and tasks cross the 30 μs threshold. This difference is probably due to the fact that a Future is a running computation while a Task is partially constructed up front and explicitly run later. So with the Future the threads might just be waiting for more work. The overhead of Task.run seems to catch up with us at around 50 steps.
But honestly the difference between these two lines is not something I would care about in a real application, because if we jump on the trampoline instead of submitting to a thread pool (green line marked Trampoline), things are between one and two orders of magnitude faster.
If we only jump on the trampoline when we really need it (red line marked Optimized), we can gain another order of magnitude. Compared to the original naïve version that always goes to the thread pool, this is now the difference between running your program on a 10 MHz machine and running it on a 1 GHz machine.
If we measure without using any Task/Future at all, the line tracks the Optimized red line pretty closely then shoots to infinity around 1000 (or however many frames fit in your stack space) because the program crashes at that point.
In summary, if we’re smart about trampolines vs thread pools, Future vs Task, and optimize for our stack size, we can go from milliseconds to microseconds with not very much effort. Or seconds to milliseconds, or weeks to hours, as the case may be.
Comments